Overview¶
APReL is a unified Python3 library for active preference-based reward learning methods. It offers a modular framework for experimenting with and implementing preference-based reward learning techniques; which include active querying, multimodal learning, and batch generation methods.
Not sure what preference-based learning means? Read on or check our video for a simple example.
Introduction¶
As robots enter our daily lives, we want them to act in ways that are aligned with our preferences, and goals. Learning a reward function that captures human preferences about how a robot should operate is a fundamental robot learning problem that is the core of the algorithms presented with APReL.
There are a number of different information modalities that can be avenues for humans to convey their preferences to a robot. These include demonstrations, physical corrections, observations, language instructions and narrations, ratings, comparisons and rankings, each of which has its own advantages and drawbacks. Learning human preferences using comparisons and rankings is well-studied outside of robotics, and the paradigm of learning human preferences based on comparisons and rankings shows promise in robotics applications as well.
However, preference-based learning poses another important challenge: each comparison or ranking gives a very small amount of information. For example, a pairwise comparison between a trajectory of a car that speeds up at an intersection with another trajectory that slows down gives at most one bit of information. Hence, it becomes critical to optimize for what the user should compare or rank. To this end, researchers have developed several active learning techniques to improve data-efficiency of preference-based learning by maximizing the information acquired from each query to the user. APReL enables these techniques to be applied on any simulation environment that is compatible with the standard OpenAI Gym structure.
In essence, APReL provides a modular framework for the solutions of the following three problems:
How do we learn from user preferences after optionally initializing with other feedback types, e.g., demonstrations?
How do we actively generate preference/ranking queries that are optimized to be informative for the learning model?
How do we actively generate batches of queries to alleviate the computational burden of active query generation?
Structure of APReL¶
Let’s now briefly look at APReL’s modules to see how it deals with solving these problems. These modules include: query types, user models, belief distributions, query optimizers and different acquisition functions. An overview of APReL’s general workflow is shown below. We next briefly go over each of the modules.
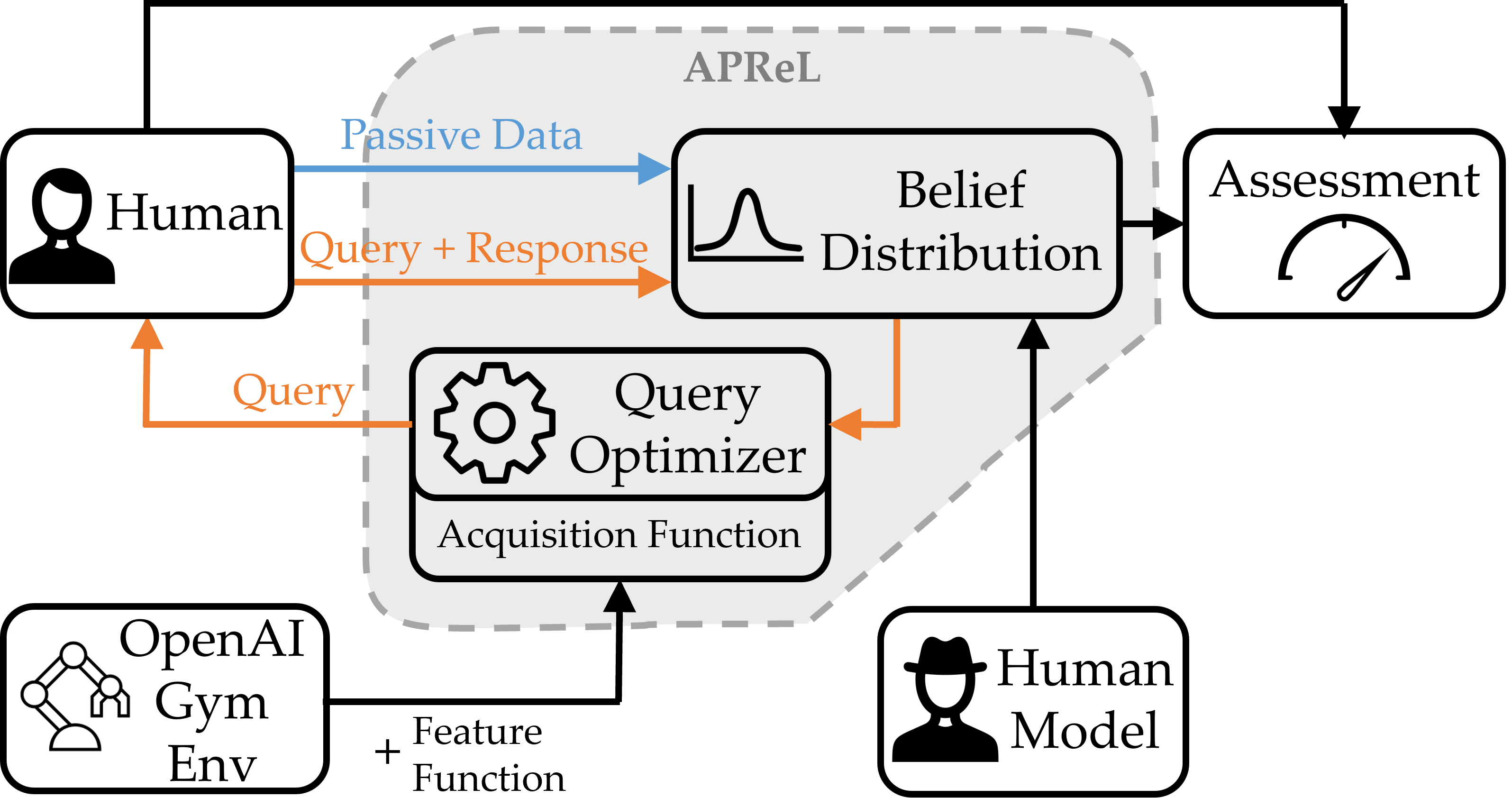
Basics¶
APReL implements Environment and Trajectory classes. An APReL environment requires an OpenAI Gym environment and a features function that maps a given sequence of state-action pairs to a vector of trajectory features. Trajectory instances then keep trajectories of the Environment along with their features.
Query Types¶
Researchers developed and used several comparison and ranking query types. Among those, APReL readily implements preference queries, weak comparison queries, and full ranking queries. More importantly, the module for query types is customizable, allowing researchers to implement other query types and information sources. As an example, demonstrations are already included in APReL.
User Models¶
Preference-based reward learning techniques rely on a human response model, e.g. the softmax model, which gives the probabilities for possible responses conditioned on the query and the reward function. APReL allows to adopt any parametric human model and specify which parameters will be fixed or learned.
Belief Distributions¶
After receiving feedback from the human (Human in the figure above), Bayesian learning is performed based on an assumed human model (Human-hat in the figure) by a belief distribution module. APReL implements the sampling-based posterior distribution model that has been widely employed by the researchers. However, its modular structure also allows to implement other belief distributions, e.g., Gaussian processes.
Query Optimizers¶
After updating the belief distribution with the user feedback, a query optimizer completes the active learning loop by optimizing an acquisition function to find the best query to the human. APReL implements the widely-used “optimize-over-a-trajectory-set” idea for this optimization, and allows the acquisition functions that we discussed earlier. Besides, the optimizer module also implements the batch optimization methods that output a batch of queries using different techniques. All of these three components (optimizer, acquisition functions, batch generator) can be extended to other techniques.
Assessing¶
After (or during) learning, it is often desired to assess the quality of the learned reward function or user model. The final module does this by comparing the learned model with the information from the human.
Citations¶
Please cite APReL if you use this library in your publications:
@article{biyik2021aprel,
title={APReL: A Library for Active Preference-based Reward Learning Algorithms},
author={B{\i}y{\i}k, Erdem and Talati, Aditi and Sadigh, Dorsa},
journal={arXiv preprint arXiv:2108.07259},
year={2021}
}